
SurvivoRAPM
Applying the regularized adjusted plus-minus framework to 50 seasons of Survivor challenge data

All in all, I think Luke’s Basketball Substack is a pretty good name. I’m Luke. I write about basketball on Substack. It covers the who, what, and where of this passion project, which seems like something a name should do. A big downside, however, is that I sometimes don’t want to write about basketball. But Luke’s Sometimes Basketball Substack doesn’t quite hit the same. I could start Luke’s Not Basketball Substack, but then I may lose my captive audience. So, apologies for this non-basketball substack post on Luke’s Basketball Substack. It’s at least basketball-inspired!
I watch Survivor every week. Usually, when I tell people this, they say something like “I didn’t know that was still on” or “I didn’t know people still watch that.” It is, and we do.
For those unaware, Survivor drops a bunch of strangers on a beach, splits them into tribes, and eliminates one person every few days by vote. The last one standing wins a million dollars. It's been running for 50 seasons and over 750 players. It’s a beautiful study of game theory in a lot of ways. Alliances form, information is asymmetric, people lie, and coalition dynamics are at play.
Before votes happen, tribes compete in physical and mental challenges. Losing a challenge means your tribe goes to Tribal Council, where someone gets voted out. So challenge performance has direct strategic consequences—winning keeps you safe, losing forces your alliance to make hard decisions. There are also individual challenges later in the game, where one player wins immunity from that night's vote.
As I’ve watched the current season (Season 50), I’ve thought a lot about challenge success. Early in the game, tribes focus on challenge strength, but it often just seems like they focus on physical strength as a proxy. I’m not sure that’s totally right.
So I tried to build a model. Luckily for us (me), there is a whole R package of Survivor data, called survivoR.
RAPM
In basketball, Regularized Adjusted Plus-Minus isolates individual player impact from lineup noise. A player's on-court minutes are shared with four teammates against five opponents. RAPM uses ridge regression across thousands of possessions to tease out who's actually moving the needle. This pair of posts by Jeremias Engelmann is required reading that will describe it all much better than I can:

Survivor challenges have a structure that lends itself well to this type of project. Tribal challenges are between tribes of varying sizes. Each tribe is a lineup. Win or lose is the outcome. The underlying question is the same: controlling for who else is in the competition, how much does this player's presence change the probability of winning?
I modified the general framework a bit in ways that hopefully made it more useful for Survivor challenge purposes:
Tribe-size normalization. Basketball RAPM normalizes by possession. Here, we normalize by tribe size. A player on a winning 4-person tribe gets a design matrix entry of 1/√4 = 0.50, while a player on a winning 9-person tribe gets 1/√9 = 0.33. Winning with fewer teammates is stronger evidence of individual impact.
Challenge-type weighting. Immunity challenges are weighted 1.5× vs. 1.0× for reward challenges. I assume players try harder when their life is on the line. It’s sort of like weighting playoff minutes more heavily than regular season in NBA models.
Bradley-Terry individual model. Individual challenges (including duels) are modeled as pairwise comparisons: the winner gets +1 in their column, the loser gets −1, and the target is always +1. These ratings are z-scored and combined with tribal ratings at a 40/60 weight.
Skill decomposition. The survivoR package tags each challenge with up to 33 boolean skill flags. We group these into five categories—puzzle, physical, precision, water, and balance—and fit separate RAPM models on each subset. This attempts to get at my intuition that challenge strength and physical strength are quite different.
Results
The distribution of Overall RAPM across 620 qualifying players (minimum 5 challenges) is roughly normal with a slight right skew. The model's ridge penalty pulls everyone toward zero. The idea is that sustained, consistent impact across many tribal and individual challenges moves a player into the tails.
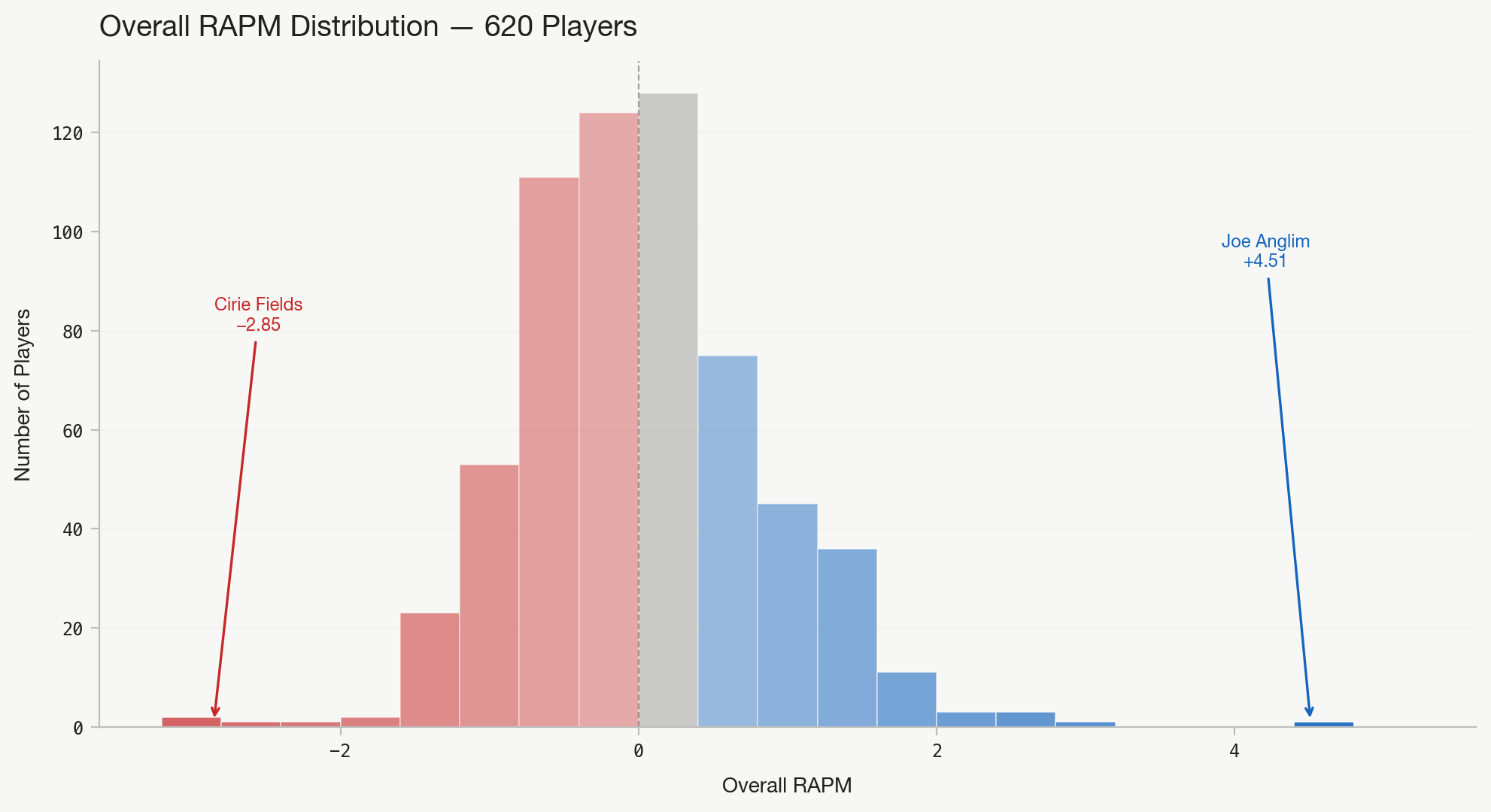
Overall RAPM is a weighted average of z-scored tribal and individual ratings (60/40) split. N is total challenge appearances, with a minimum of 5 to qualify. Here is what the top and bottom 25 looks like:
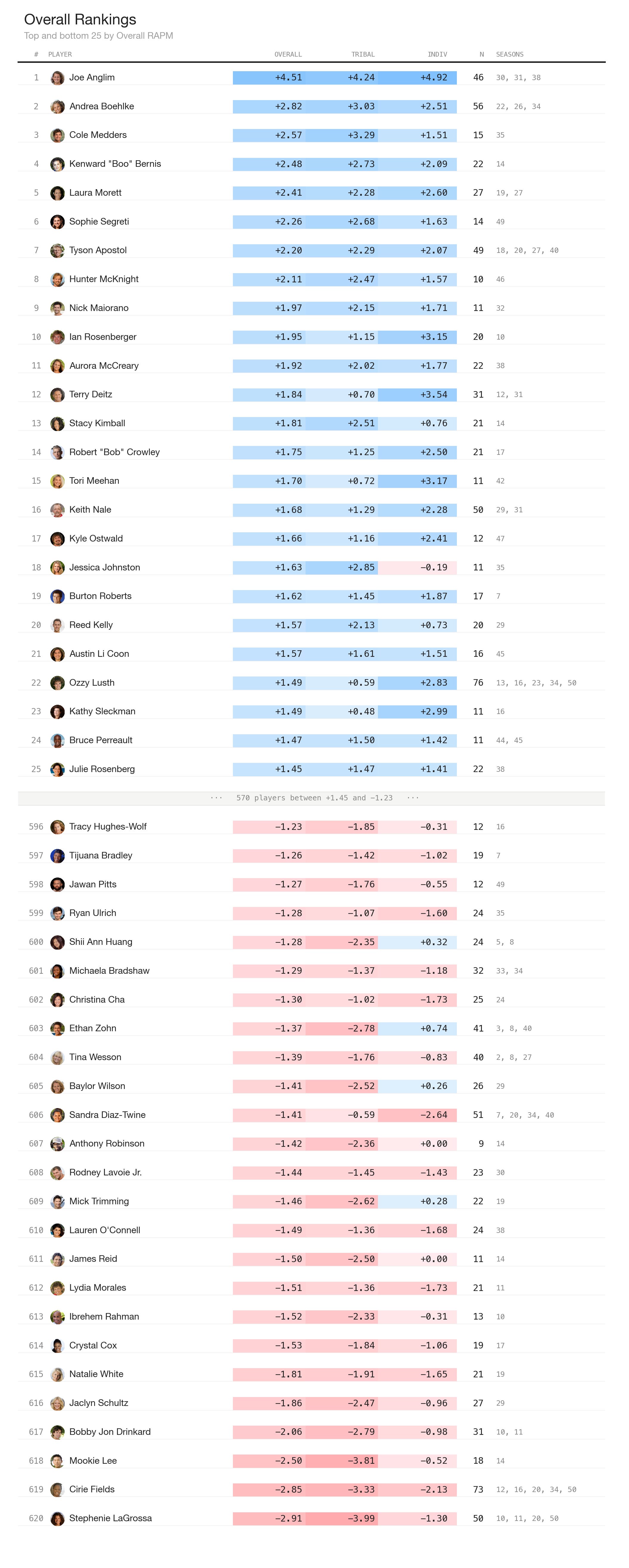
It’s probably a good sign that Joe Anglim is first. I once heard Seth Partnow say that there’s this thing called the “Messi Test” in soccer; if you make a metric and Messi isn’t at the top, it’s a bad metric. I think this passes the Messi Test.
We can also view this in quadrant form. The x-axis measures how much a player lifts their tribe in team challenges (controlling for tribemates). The y-axis measures head-to-head individual performance.
Skill Decomposition
Each challenge in the dataset is tagged with up to 33 boolean skill flags. We group these into five categories and fit separate RAPM models on the subset of challenges matching each tag. This is analogous to splitting basketball data by play type.
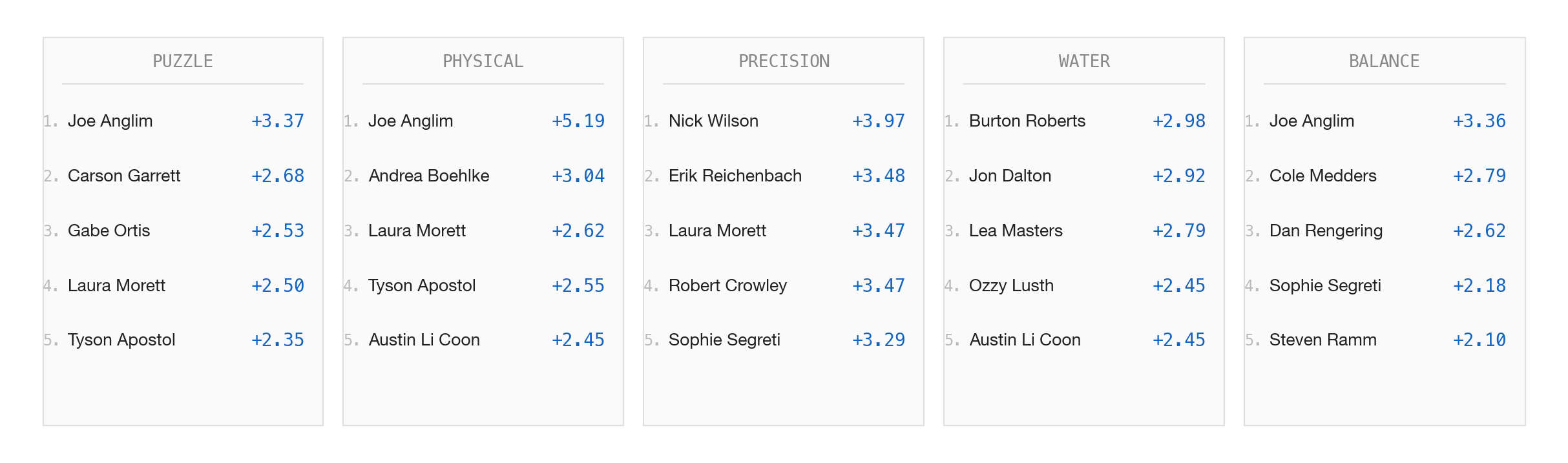
Here’s a look at the top 5 leaders in each category:
Physical Dominance
This is the point of the post where I discover that my intuition that physical strength is overvalued was probably wrong. Physical RAPM explains ~93% of the variance in Overall RAPM. No other skill dimension really comes close.
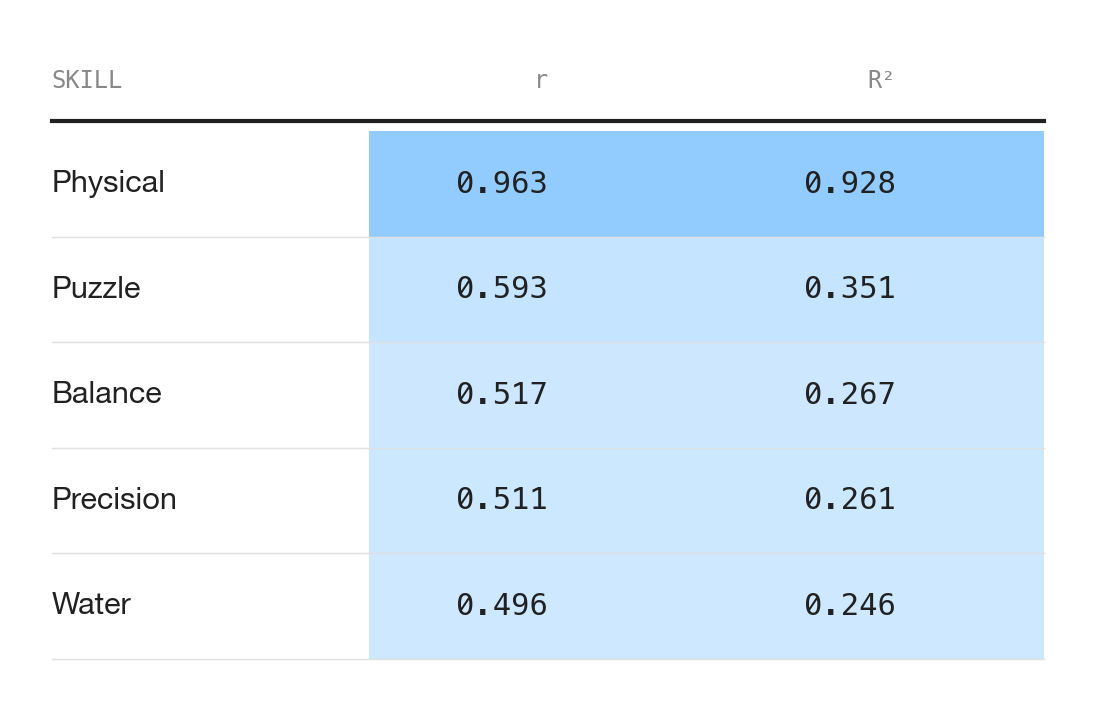
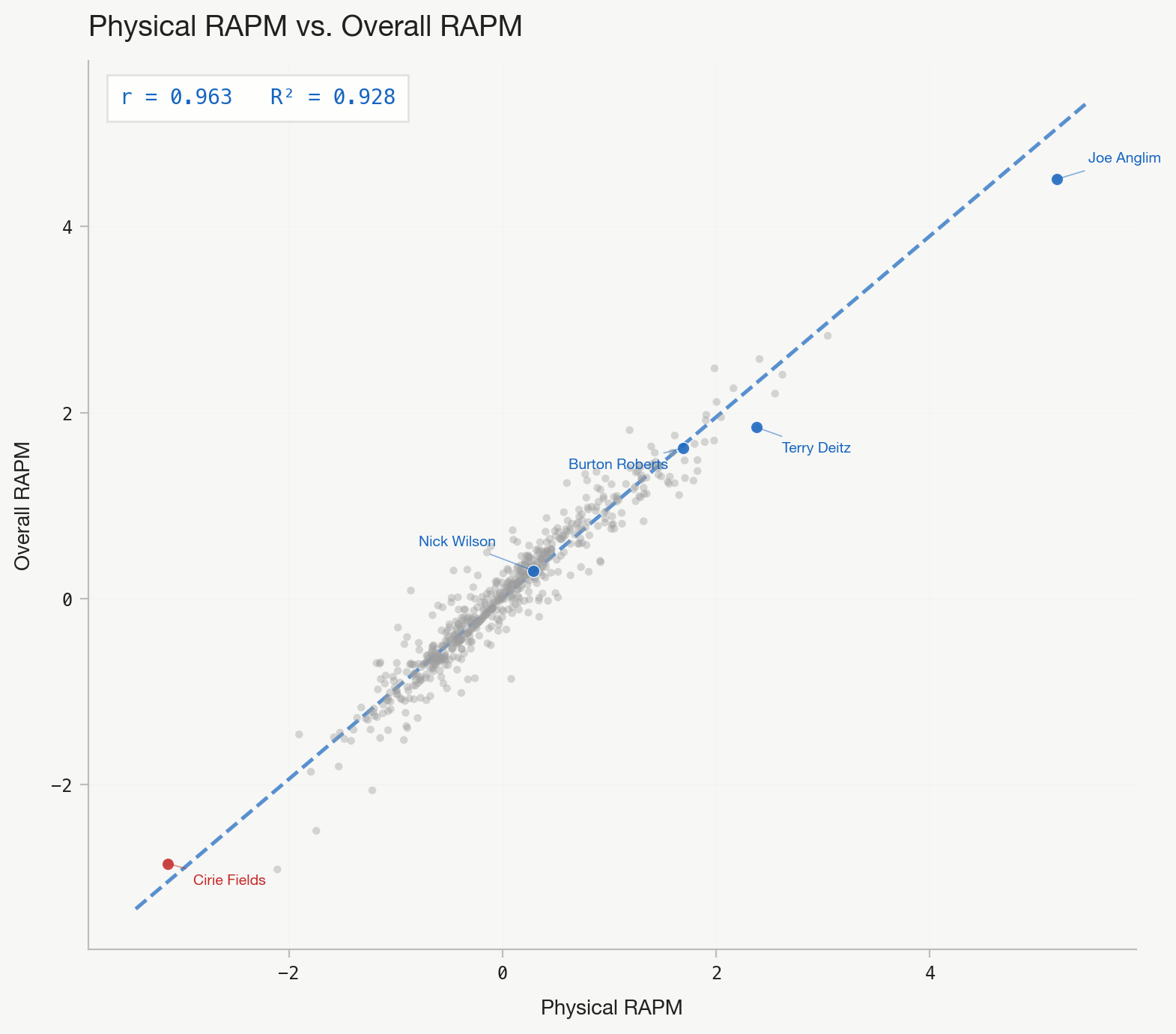
Though this is a little misleading. Of the 1,141 unique challenges in the dataset, 94.3% carry a Physical tag. A "puzzle challenge" is usually a physical obstacle course with a puzzle at the end. A "water challenge" means swimming plus a physical component onshore. The Overall rating is, in practice, a Physical rating with contributions from other dimensions at the margins. The skill decomposition is most useful for identifying specialists who diverge from the physical baseline: precision snipers like Nick Wilson, water threats like Ozzy, or puzzle savants like Carson Garrett.
But Physical doesn't explain everything. When we plot Physical against Tribal RAPM alone, the R² drops to 0.522. The scatter is visibly noisier.
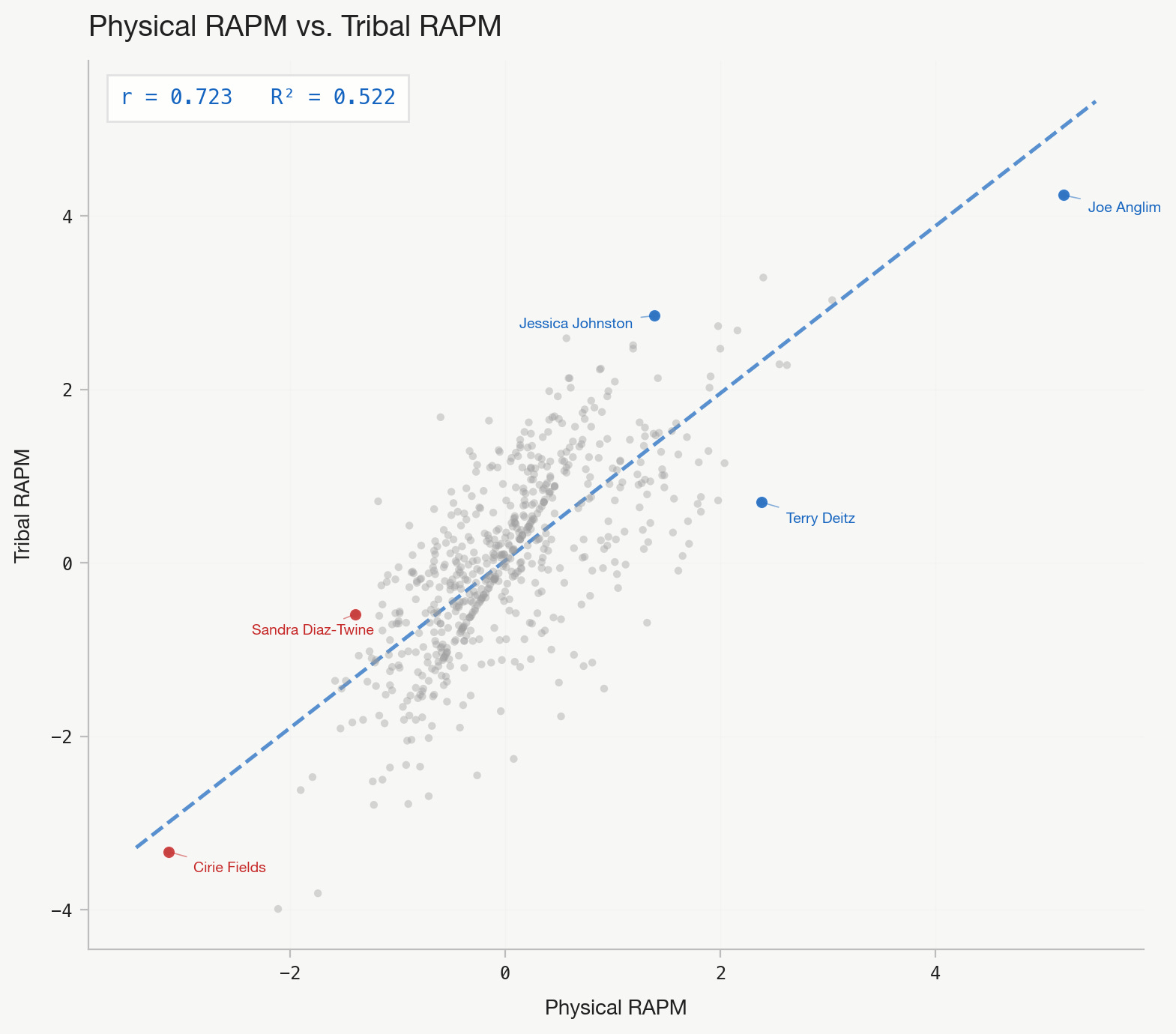
This leads me back to thinking my intuition isn’t totally wrong. The conventional Survivor move is to keep physically strong players around pre-merge because they help your tribe win challenges, then vote them out before they dominate individual immunity.
Physical RAPM only explains 52% of Tribal RAPM variance—puzzles, water crossings, and coordination matter just as much. A strong player's tribal contribution is also diluted by tribe size: on an average tribe of 6, each player's impact is scaled by 1/√6, roughly 41% of their full ability. That benefit is shared across the whole tribe. After the merge, that same player brings 100% of their strength to individual immunity, directly against you. The math is asymmetric: you're renting a fraction of their ability pre-merge, then facing all of it post-merge.
And yet, in practice, it doesn't seem to matter. Physical RAPM has essentially zero correlation with how long a player survives (r = 0.045, p = 0.26). Top-quartile physical players survive 72.5% of their season's challenges; bottom-quartile survive 70.2%. Challenge threats do get targeted after the merge, but they also win immunity when they need it most. The two effects largely cancel out.
Ultimately: the tribal value of a strong player is probably overstated. Their contribution to your tribe is diluted and only half-explained by raw physicality. Their threat to your individual game post-merge is concentrated and direct. If anything, the RAPM data probably suggests tribes should be less inclined to protect challenge threats than conventional wisdom holds.
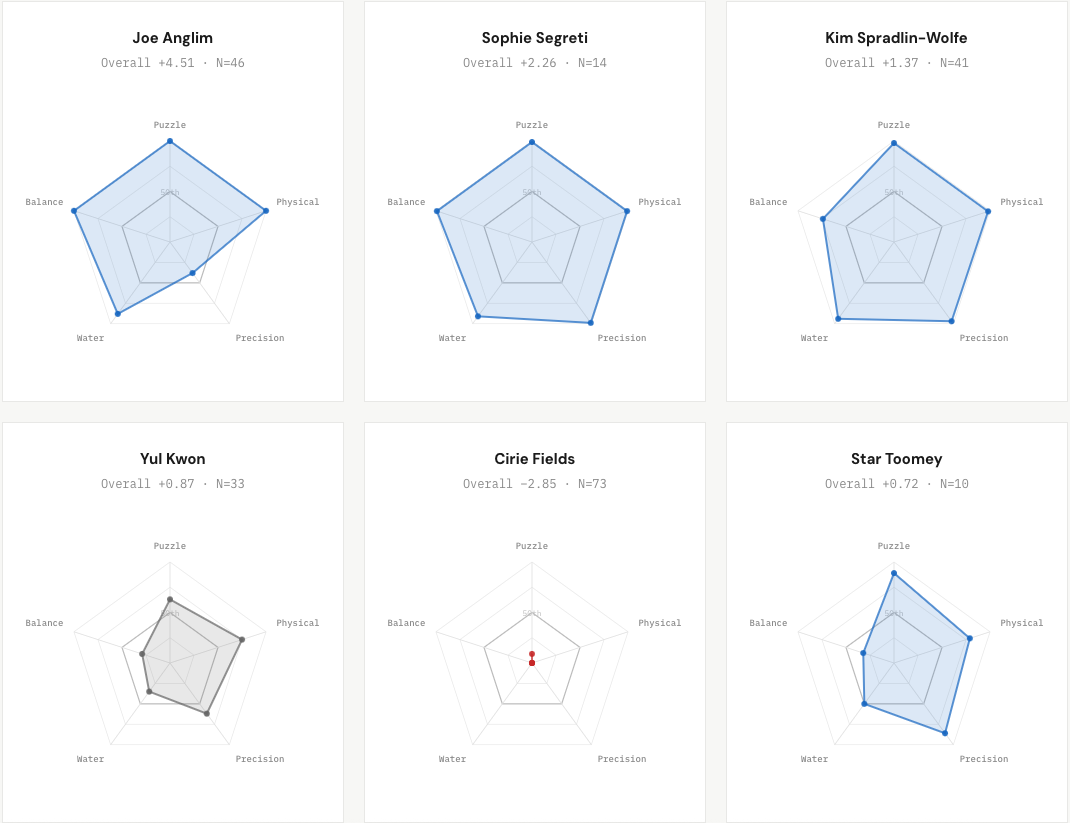
Skill Profiles
We can also use this RAPM data to visualize player skill performance. Here are some radar charts across five skill dimensions of some of my favorite players:
Big Ol’ Table of Data
For your reference:
Basketball stuff is on the way, too.
Who is Cirie Fields and how did she end up on 5 seasons of the show if she was seemingly so bad?